Motivation
For any reasonably complex system, it is necessary to ensure that the system is acting as intended without any unpredictable behaviours that may end up compromising the system and/or the systems surrounding it. There are many safety critical systems whose malfunctioning can cause innumerable casualties and loss of life, thus for these systems we need to reliably prove that they have predictable outputs corresponding to determined inputs.
Formal Verification utilizes a lot of different mathematical tools to demonstrate the “correctness” of some system with respect to some desirable specification or property. The set of tools used for Formal Verification is collectively known as Formal Methods and include such theories like logic, automata, type systems and formal languages. These can be used to check the behaviour of some system against a set of specifications in order to determine correctness of the system. Formal Verification can be imagined as a layer of abstraction on top of systems (both software and hardware) that provides some guarantees as to the functioning of these systems.
Below we will be building up to the application of Formal Methods to the field of Machine Learning in order to Verify Neural Networks.
Note
The following is an effort to condense the Introduction to Neural Network Verification book in order to concisely summarize the material that is relevant to my research.
Introduction
Background
One of the first demonstrations of the possibilities of verification came from Alan Turing’s 1949 paper called ‘Checking a large routine’. In the paper the program for finding the factorial of a number was broken down into a simple sequential set of instructions that could either be either or . The truth values for each of these assertions were then checked in order to prove that the program is a faithful implementation of the factorial mathematical function. This is known as proving the functional correctness of a program. Although this is the gold standard for demonstrating correctness, it is not possible to do so for Neural Networks as the tasks performed cannot be described mathematically. In a Neural Network we generally test for the following qualities:
- Robustness: This class of properties is violated when small perturbations to the inputs result in changes to the output. It also measures how well a model performs on new and unseen test data.
- Safety: This is a broad class of correctness properties that ensure that the program does not reach a ‘bad’ state. (e.g., a surgical robot should not be operating at 200mph)
- Consistency: This class of properties are violated only when the algorithms are not consistent with the real world. (e.g., tracking an object in free fall should be consistent with the laws of gravitation)
We will mostly be testing for Robustness, as that is the set of properties that are most widely tested for. It can also encapsulate the Safety and Consistency classes (as there is not well-defined boundary between them) if the specifications are designed accordingly.
Note
Alan Turning had also extensively thought about ‘Networks that can Learn’, which can be seen from his 1948 paper Intelligent Machinery where he proposes Boolean NAND networks that can learn over time.
Abstraction of Neural Network
We will not be dealing with the technicalities of the Neural Networks but rather used well-rounded mathematical abstractions that can be rigorously tested over. Since all Neural Networks can be though of as Directed Acyclic Graphs (DAGs), we will be treating them as such. More specifically they will be treated as dataflow graphs of operators over . The shape of these graphs will determine what specific architecture they belong to. Each node will perform some computation, whose dependencies are the edges. Thus, a neural network will be associated with some function:
For a Neural Network: , we have:
: finite set of nodes
: set of edges
: input nodes
: output nodes
: total number of edges whose target is
where, and for the network.
All neural networks are finite DAGs, there are classes of neural networks called Recurrent Neural Networks that have loops, but the number of iterations will depend on the size of the input. RNNs have self-loops that unroll based on the length of the input, which means that it reliably terminates. So while testing neural networks we will not test for loop termination and the explosion of possible program paths that comes with it.
For our purposes the following conditions must be met in a network:
- all nodes must be reachable from some input node
- every node can reach an output node
- fixed total ordering on edges and another one on nodes .
Each node of the neural network is a function of the following form:
Where each node takes in some vector, does some computation on it and return a single output number that is passed through an activation function (a non-linear function), for ease of analysis they are treated as belonging to two different nodes. Each of the elements of the vectors are the outputs of previous nodes. These relations can be recursively defined with the base case terminating at the input nodes. Therefore, for every non-input node , we have:
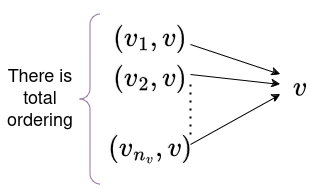
Where each represents an edge connecting node to . The ordering of these edges and nodes determines the inputs on the basis of which the computations will be done. Each node will have an function which can be defined as follows:
where for . This is the recursive definition wherein each input to the node can be defined as:
No sequence of operations are defined, only which nodes need what data to perform its computations. A more modified version of these graphs are known as computation graphs. values can be computed in any topological ordering of graph nodes, as it needs to be ensured that all the inputs need to be computed before the target node itself. The total ordering ensures proper reference to the graph nodes and whether computations have been done in their desirable sequence, below the total ordering of nodes helps linearize the nodes into a topologically sorted sequence.
flowchart LR
1(( 1 ))
2(( 2 ))
3(( 3 ))
4(( 4 ))
5(( 5 ))
6(( 6 ))
7(( 7 ))
8(( 8 ))
9(( 9 ))
10(( 10 ))
11(( 11 ))
12(( 12 ))
1 & 2 & 3 & 4 --> 5 & 6 & 7
5 & 6 & 7 --> 8 & 9
8 & 9 --> 10 & 11 & 12
subgraph input
1
2
3
4
end
subgraph hidden1
5
6
7
end
subgraph hidden2
8
9
end
subgraph output
10
11
12
end
All vector computations need to be linear: or piece-wise linear:
where and .
Note
Neural Networks are an instance of differential programs.
Defining Specifications
We define a language that specifies some properties about the functioning of a neural net. This will enable us to later on make statements and verify them based on the specifying language.
Specifications are generally of the form:
where both preconditions and post-conditions are statements that specify some property that is adjacent to input and output respectively. Properties dictate the input-output behaviour of the network (and not the internals). Specifications help in quantifying some properties for accurate verification. Each specification can be thought of as being structured in the following way:
Although every possible specification needed for complete verification cannot be made, multiple specifications can be combined together to test for stronger properties. Preconditions are generally predicates or Boolean functions defined over set of variables which act as inputs to the system, and post condition is a Boolean predicate over the variables appearing in precondition () and assigned variables ().
For any values of that make the precondition true, let , , where are the computations on the input, then the post condition must also be True.
If the post condition is False, then the correctness property is not true, i.e., the property does not hold.
Consider: c is an actual greyscale image, each element of c is the intensity of a pixel ; we can state the following specification about the brightness of c and its corresponding classification:
and are vectors whose elements are probabilities for a belonging to a class with labels corresponding to the indexes. and extract the indexes corresponding to the largest elements of the vectors and respectively.
Info
Counterexamples: Valuations of variables in precondition that falsifies the post condition.
flowchart TD
A["Verification"]
B["Constraint Based"]
C["Abstraction Based"]
A --> B & C
Constraint-Based Verification
Constraint-Based Satisfaction
A correctness property is taken and encoded as a set of constraints, solving which will help us to decide whether the property holds or not.
Let be the set of free variables appearing in the formula .
Interpretation: of is a map from variables present in to either or . denotes the formula where the variables have been replaced with their corresponding interpretations.
Example:
Let , which means that is syntactically defined to be equal to the Boolean formula (as opposed to being semantically equivalent).
: denotes the simplest form of we can get by evaluating repeatedly.
is satisfiable (SAT) if there exists an s.t. , in which case, is the model of : .
denotes isn’t a model of .
if and only if .
is unsatisfiable (UNSAT) if .
Validity: If every interpretation is a model of , then is valid.
Boolean satisfiability theories (SAT) can be generalised to more complex theories to include reals, vectors, strings, arrays, etc.; the problem of determining whether statements within these theories are true is known as Satisfiability Modulo Theories or simply SMT. We will be extensively using a first-order logic system called Linear Real Arithmetic (LRA) as it can represent a large class of neural networks and is decidable.
In LRA, each propositional variable is replaced by a linear inequality of the form:
where .
An interpretation of is an assignment of every free variable to a real number.
Encoding Neural Networks
We need to translate Neural Networks into a formula in LRA such that we can use SMT Solvers (specialised software that tests satisfiability for SMT problems).
: Function in node.
: Model.
: Encoding for node.
: Relational mapping for neural network.
Note
Generally Variables with a subscript refers to the overall neural network as a graph and those with a subscript v refers to individual nodes or a collection of nodes.
Whole Network can be defined as a binary relation:
, define the same for a single node in network.
For a single neuron with corresponding function , both can be defined as:
Thus the encoding for a node with one input is as follows
Models of will be of the form and have one-to-one correspondence with the elements of .
For two inputs: The formula for the encoding of a node with the function can be represented as
Generalizing encoding for any single node:
Formalizing the operation of some node . We assume that the function is piecewise linear, i.e., of the form
where ranges from to . This generalizes representations to allow any one linear operation corresponding to some predetermined condition . Each is defined as a formula in LRA over the elements of . Thus, the encoding for the single node can be written as:
if statement is , then is equal to the equality. The statements are combined together using a conjunction over all possible inputs () to the node. Each clause joined using the conjunction is in form providing the functionality of an if statement. So the general way to read this condensed statement is:
Example (ReLU):
The encoding for a simple ReLU function will be:
In order to ensure that we are making accurate representations of the actual system that we are modelling, we have to ensure that two qualities are always guaranteed for the encodings: Soundness & Completeness.
Soundness - This is to make sure that our model does not miss any behaviour of . Let
for any given tuple of and which is an element of , is a model of : . Soundness is the property of only being able to prove “true” things, any analysis about the system that is proven to be true, will be true.
Completeness - Any model of maps to a behaviour of , so if for a model of :
then . Completeness is the property of being able to prove all true things that can possibly exist in the system. This property can be used to determine counterexamples for any given model.
So far we have seen how to encode a singular node in a larger network. But to encode an entire Neural Net, we need to have the following structure:
flowchart TD
a[Encoding a Neural Network]
b[Encoding a formula for the nodes]
c[Encoding a formula for the edges]
a --> b
a --> c
Encoding the nodes:
for all non-input nodes we have:
Since the input nodes do not perform any operations, we are excluding them from the set using .
Encoding the edges:
For some node there exists a total ordering of edges: The total ordering tells us which edge feeds into which corresponding input index of the node.
As per the total ordering of the input edges, determines that the output of the node from the previous layer will become the input of the present node. The ‘s present in the below diagram are the sequentially ordered nodes of the previous layer.
More concretely:
The entire network can be represented as a conjunction of the edges and nodes:
Assuming that we have ordered input nodes in Let and let
Then there exists such that .
Note
Size of encoding is linear in the size of the Neural Network
Example:
flowchart LR
A["v₁"]
B["v₂"]
C(("v₃"))
D["v₄"]
A & B --> C --> D
The functions corresponding to nodes and are as follows:
The formulations for each of the corresponding nodes will be:
Encoding of :
So far we have been considering the linear operations that form the weights and biases for the nodes in a neural network, however, there are also non-linearities that are present.
How to deal with non-linear activations?
We can create representations of non-linear activation functions by over-approximation of said functions. Over-approximation is the partitioning of the function into different input domains and binding the outputs corresponding to each of these input domains to some defined output domain. For example; we can make an over-approximation for the Sigmoid () function by diving the function into appropriate intervals that roughly corresponds to its overall behaviour, i.e., anything less than a certain threshold will give us a 0, anything more than a certain threshold will give us 1 and any input values in between them will give us a value of roughly 0.5.
The above can be generalized to any monotonically increasing or decreasing function (which is all activation functions). Assume is monotonically increasing, sample a sequence of real values
where and are the *lower bound and upper bound respectively. A point to note in the case of over-approximations are that they will give us soundness, but not completeness. Completeness essentially means that our encoding can find counterexamples, which we are abandoning in this case. Soundness means being able to prove correctness properties using an encoding, which is of highest priority for our models.
A Concrete Example for checking Robustness
Where the output vectors in correspond to:
Let the specification for this be:
where is the original image and is the perturbed image. The formula generated to check this statement is called a Verification Condition (VC), which if valid then ensures that the correctness property holds.
inputs: outputs: Neural Network:
LRA does not support vector operations hence the vector operations are decomposed into their constituent scalars. Absolute value operators are also not available in LRA, so we encode them as: . We need to connect variables of with inputs and output .
For multiple Neural Networks, Correctness Properties have the form:
For the above specification we have:
For the above corresponds to . combines encoding of the neural network along with connections with inputs and outputs, and , respectively.
(soundness) If is valid, then the correctness property is true. (completeness) If it is invalid, we know there is a model if is encodeable in LRA.
Assuming, input and output variables of the encoding of are and ; each graph has unique nodes and therefore input/output variables.
The above reads as: “If the precondition is true and we execute all networks, then the postcondition should be true”
Example:
where .
We take the input value to be equal to 0.99: . This is a valid value of as per the defined precondition.
Therefore, we have:
is invalid as , thus the correctness property does not hold.
Info
In the formulations that we have gone over, disjunctions arise due to the ReLU function, due to its active/inactive states for all possible inputs to the Neural Network. Disjunctions cause problem during solving, as without them LRA (and a similar system called MILP) are polynomial time solvable. To solve LRAs with disjunction we either simplify the formulations by using lightweight techniques to discover whether ReLUs are active or not (abstraction-based verification). Alternatively, we can add additional bias to make all the ReLUs either always active or always inactive. Another thing to consider is that verified NNs in LRA may not really be robust when considering bit-level behaviour.
DPLL (Davis-Putnam-Logemann-Loveland)
DPLL algorithm checks the satisfiability of Boolean formulae and underlies modern SMT and SAT solver. An extension of DPLL algorithm is needed to handle first-order formulae over different theories.
Conjunctive Normal Form (CNF)
DPLL expects formulae that will be inputted to be in the shape of Conjunctive Normal Form (CNF), all Boolean formulae must be written in CNF as can be seen below
where each sub-formula is called a clause and is for the form
where each is called a literal and is either a variable () or its negation (). Thus the structure of an entire input should be in the form:
flowchart TD
C_1((C₁))
C_2((C₂))
C_n((Cₙ))
l_1((l₁))
l_2((l₂))
l_m((lₘ))
p((p))
np((¬p))
d1([......])
d2([......])
C_1 --> l_1 & l_2 & l_m
l_1 --> p & np
subgraph Clauses
C_1 -. ∧ .- C_2 -. ∧ .- d1 -. ∧ .- C_n
end
subgraph Literals
l_1 -. ∨ .- l_2 -. ∨ .- d2 -. ∨ .- l_m
end
subgraph Variables
p
np
end
DPLL has the following two alternating phases
flowchart LR
A(["Deduction"])
B(["Search"])
A --> B --> A
Deduction
Boolean Constant Propagation (BCP)
The algorithm searches the Boolean CNF for clauses with single literals, i.e., clauses that contain only one Boolean variable instead of disjunctions of multiple literals. For a model to be satisfiable, the single literal must be if the variable is or if the variable is .
The BCP phase will look for all unit clauses and replace their literals with .
Example:
Thus is SAT with the model
Deduction + Search
DPLL:
Data: A formula F in CNF
Result: I ⊧ F or UNSAT
▹ Boolean Constant Propagation (BCP)
while there is a unit clause (l) in F do:
Let F be F[F ↦ True]
if F is True then return SAT
▹ Search
for every possible variable in F do:
If DPLL(F[p ↦ True]) is SAT then return SAT
If DPLL(F[p ↦ False]) is SAT then return SAT
return UNSATThe model that is returned by DPLL when the input is SAT is maintained implicitly in the sequence of assignments to variables (of the form and ).
DPLL returns SAT and then implicitly builds the model for :
Partial Model: DPLL can terminate with SAT and without assigning values to each and every variable, these incomplete models are called as partial models. The unfilled variables are essentially don’t care variables and can be filled in any way we want. For , is a partial model.
DPLL Modulo Theories
DPLL modulo theories or DPLLᵀ are extensions of DPLL over formulae in mathematical theories such as LRA. We essentially treat a formula completely by taking it as a Boolean, then incrementally add more and more theory info to conclusively prove SAT or UNSAT.
flowchart LR
A[Original Formula
F]
B[Boolean Abstraction
Fᴮ]
A --B---> B --T---> A
DPLLᵀ Algorithm

Constraints are lost in the abstraction process () such as the relation between the different inequalities. If is UNSAT, then is UNSAT, but, if is SAT, it does not imply that is SAT.
The DPLLᵀ algorithm first uses DPLL to check if is UNSAT following the properties of abstraction. IF is SAT, we will take the model returned by DPLL() and map it to the formula in the theory we have abstracted the theory from (LRA in our case). If the theory solver deems satisfiable, is satisfiable. Otherwise, DPLLᵀ learns that is not a model so it negates and conjoins it to . DPLLᵀ lazily learns more and more facts about the formula and refines the abstraction until the algorithm can decide SAT or UNSAT. The whole process is illustrated below:
flowchart LR
FU([F is UNSAT])
FB((Fᴮ))
I((I))
IT([Iᵀ])
FS([F is SAT])
NI((¬I))
FB --SAT---> I --T--> IT --SAT---> FS
FB --UNSAT---> FU
IT --UNSAT---> NI --∧---> FB
DPLL takes care of the disjunctions by taking clauses and searching for satisfiability by mapping literals to or values. DPLL assumes access to a theory solver to take care of the conjunctions of linear inequalities, in order to check their satisfiability. For LRA, the Simplex Algorithm can be used as a theory solver.
Example:
How to convert Boolean formulae into CNF? Usually we use De Morgan’s Law (however all are ) What can be used: Tseitin’s Transformation ()
Tseitin’s Transformation
Any model of is also a model of , if we disregard the interpretations of newly added variables. If is UNSAT, then is UNSAT, so we just need to invoke DPLL on .
Tseitin’s transformation changes a formula of computations into a set of instructions, each containing one or two variables, connected by a single unary or binary operator respectively. For example:
def f(x, y, z):
pass
return x + (2*y + 3)The above function can be decomposed into a set of instructions, that when executed sequentially will provide the same result. For the above example, the function can be decomposed into the following instructions:
def f(x,y,z):
t1 = 2 * y
t2 = t1 + 3
t3 = x + t2
return t3If we are able to conjoin these sequential set of instructions, we will be converting the complex computation in non-CNF to CNF with added temporary variables ; Tseitin’s transformation follows a similar procedure over Boolean formulae to generate a CNF.
Tseitin Step 1: NNF
Negation Normal Form (NNF) is achieved by pushing negation inwards so that only appears next to variables, e.g., instead of .
Tseitin Step 2: Subformula Rewriting
Any subformula of that contains a conjunction/disjunction is called a subformula. We don’t consider subformula at literal level.
are the deepest level of nesting, is subformula of . And all are subformulae of .
Assuming has subformulae:
- For every subformula of , create a fresh variable . These variables are analogous to the temporary variables that was introduced to decompose some complex program
- Starting with the most deeply-rooted subformula: let be of the form , where is or and are literals. One or both of and may be the new variable denoting a subformula of , create the formula:
These formulae are analogous to the assignments to temporary variables in code, where is the logical analogue of variable assignment (=).
each is assigned true iff subformula evaluates to true. The constant in says that must be true, is like a return statement.
Theory Solving
Theory solver for LRA receives formula as a conjunction of linear inequalities
Goal: Check SAT for and discover .
The Simplex Algorithm will be used as a theory solver, and it expects formulae to be conjunctions of equalities of the form and bounds of the form , . The infinities are included to ensure that variables with no upper/lower bounds are also adequately represented.
Converting inequalities into simplex (slack) form:
where : Slack Variable (analogous to tseitin temporary variables)
Let be the simplex form of some formula . Then we have the following guarantees (analogue of Tseitin Transformation for non-CNF formulae):
- Any model of is a model of , disregarding assignments to slack variables.
- If is UNSAT, then is UNSAT.
Simplex Algorithm
Goal: Find a satisfying argument that maximizes some objective function. Our interest in verification is to find any satisfying assignment, so it will be a subset of Simplex.
The set of variables in simplex form is classified into two subsets:
- Basic Variables: those that appear on the left hand side of the equality; initially basic variables are the slack variables.
- Non-Basic Variables: all other variables.
At the beginning, basic variables: and non-basic: , as Simplex progresses, formulae are rewritten so some basic variables may become non-basic and vice versa.
Simplex simultaneously looks for a model and a proof for unsatisfiability. Each equality defines a halfspace (something that splits into two parts). Simplex starts from and toggles the values to satisfy all of the equalities. We are total ordering our variables to make it easier to refer to specific variables. We assumes variables are of the form . Given a basic variable and a non-basic variables , we will use to denote the coefficient of in the equality
for variable , and denotes its lower and upper bound. (Non-Slack variables have no bounds)
Two invariants that are maintained in Simplex:
- always satisfies the equalities, so only bounds may be violated; initially true as all in .
- Bounds of all non-basic variables are satisfied; initially true as they have no bounds.
For , we need to update using any non-basic var . Pick any with . If no such exists that satisfies our condition UNSAT Increase current interpretation by , interpretation of increases by , barely satisfying the lower bound, i.e., .
After updating , there is a chance that we might have violated the bounds of so we rewrite the equation such that becomes the basic variable and becomes the non-basic variable. The pivot operation follows as:
where is the set of indices of non-basic variables. For Simplex basic variables are dependent variables and non-basic variables are independent variables.

Example:
Converting the set of equations into their slack form:
Ordering and apply first model:
and are satisfied, is not: but .
Modulate the first element in our ordering: Decrease to to meet ‘s bounds.
Now we pivot with unchanged bounds:
, bound not satisfied.
New ordering of variables: value increased by
At this point we pivot with
Simplex terminates as .
Simplex terminates due to the fact that the variables are ordered and we always look for the first variables violating bounds (Bland’s Rule), this ensures that we never revisit the same set of basic and non-basic variables.
Note
Basic variables are dependent variables and Non-Basic variables are independent variables.
Using Simplex as the theory solver within DPLLᵀ allows us to solve for LRA, but this approach is not scalable as ReLUs are encoded as disjunctions. This is because the SAt-solving part of DPLLᵀ will handle it and consider every possible case of disjunction (active = x, inactive = 0), leading to many calls to Simplex, so we extend Simplex to Reluplex.
Reluplex
Equations in reluplex form:
- equations (same as simplex)
- bounds (same as simplex)
- ReLU constraints of the form: (also add bound(s) implied by relu)
We call simplex on the weaker version (less constrained) formula of called , which does not have any relu constraints. If is UNSAT, then is UNSAT.
If Simplex returns , it may not be that satisfies . If , we pick one of the violated relu constraints
and modify to make sure that it is not violated. If any of or are basic, we pivot it with a non-basic variable. The pseudocode for Reluplex Algorithm can be found below:

Note: Without Case Splitting, reluplex might not terminate - it may get stuck in a loop where the Simplex satisfies all bounds but violates a relu, then satisfying that relu causes a bound to be violated and so on.
We try to count whether a relu constraint has not been attempted to be fixed for more than times. is split into two cases: and . Reluplex is recursively invoked on the two instances of the problem: and .
If any of the instances are SAT, then is SAT.
Abstraction Based Verification
Approximate (or Abstract) techniques for verification can have two possible outcomes:
- If they succeed, they can produce proofs of correctness for a neural network.
- If they fail, we do not know whether the correctness property holds or not.
Abstraction Based Verification techniques require specific techniques in order to abstractly define a domain of inputs to be given to a modified version of a neural network in order to test their robustness. There are mainly three ways of abstracting input domains for verification: Interval Abstraction, Zonotope Domain Abstraction and Polyhedra Domain Abstraction.
flowchart TD
A["Abstraction Techniques"] --> B["Interval"] & C["Zonotope"] & D["Polyhedra"]
In Interval Abstraction, we define an interval for each of the entire set of variables/predicates independently of each other, thereby defining a rectangular structure in some high dimensional space (hyperrectangles).
In Zonotope Domains, instead of defining hyperrectangles, the input domain is defined as a collection of parallelograms superimposed on each other created using auxiliary variables called generators whose values range from -1 to 1, each generator has its corresponding coefficient values which help in making a convex structure. The main difference between zonotopes and interval domains is that we can encode the relations between multiple variables/predicates using the generators.
In Polyhedra Domain, we have a setup similar to that of Zonotope Domains, however instead of the generator values ranging from -1 to 1, we have a set of linear inequalities bound together via conjunctions that determine the overall convex shape of the interval we are defining.
These techniques have been described in more detail below:
Neural Interval Abstraction
Using the specifications that have been defined beforehand, we see that it defines a system to test for individual images through a particular neural network.
There is a great number of possible images that can be tested for, so we will try to lift the function to work over a set of images instead in order to comprehensively test for possible examples. Thus we want to transform the neural network computation that is represented by
to
where is the power set of set . Thus, the newly defined mapping from a set of elements () to the set of all predictions corresponding to all elements of will following form:
where is a set that is defined as per the specifications as the set of all that are valid under the precondition. Which for our example will be:
To verify our property, we simply check:
all runs of on every image result in network predicting class . We are defining set of inputs using data structures that we can manipulate called abstract domains. So we are taking a Neural Network and generating a version that can take a potentially infinite set of images, however during this abstraction process we will also be losing some precision, as we will be seeing soon. is called the concrete transformer of .
Example: The function is: Corresponding concrete transformer:
Interval Abstract Domain considers an interval over where and
We simplify concrete transformer by considering only sets which have a nice form (Abstract Interpretation).
is the abstract transformer of . Interval is infinite (considering ) so adds to an infinite set of reals. Expanding the above to any arbitrary dimension we have a n-dimensional interval (hyperrectangle) region in , i.e., set of all n-ary vectors
Soundness: We need to ensure that the designed is a sound approximation of . Output of should be a superset of , as we do not want to miss any behaviour. For any interval , we have: . Equivalently, for any , we have: Although in practice we often see:
We are modifying the functions to take in intervals of inputs and output the interval that contains the set of all the mappings from the input interval. However, the interval domain cannot capture the relations between different dimensions (non-relational)
Best we can do is define the unit square between and which is denoted as the 2D interval . defines points where higher x-coordinates correspond to higher y-coordinates. Our abstract abstract domain can only represent rectangles whose faces are parallel to the axes. So instead of capturing the relation between two dimensions, we are simply saying that any value that is in for can correspond to any value of in , thereby overapproximating for the function to the extent that we are unable to conserve any information about the relations between the two elements of the input.
Example 1: Consider
is defined as
is defined as a function that takes two intervals (a rectangle) representing range of values for and
Take any By definition, and , so thus proving soundness.
Example 2: Consider For only positive inputs to : However,
We were expecting but we got which would mean that the result is not a proper interval. Thus we have to compute the interval domain in a different way:
where
For the above numerical example we therefore have:
These were all basic abstract transformers that overapproximate for some given binary function.
Affine Function:
where , we can define the abstract transformer as:
where and , trying to cover the largest area possible.
Example:
Monotonic Function:
Example: ReLU in the domain Therefore,
Composing Abstract Transformers:
For we do not need to define a different transformer, we can define one for and one for and compose them to find a sound abstract transformer of :
Example: , and Affine followed by ReLU and output in
Abstractly Interpreting Neural Networks
For a network we have: where
- takes intervals and outputs intervals
- for every output node : (note: we have a fixed ordering of nodes)
- for every non-input node : where is the abstract transformer of and has incoming edges
- the output of is the set of intervals where are output nodes
Example:
:
flowchart LR
v1((v₁))
v2((v₂))
v3((v₃))
v4((v₄))
o["[2,5]"]
v1 --[0,1]--> v3
v2 --[2,3]--> v3
v3 --[2,5]--> v4 --> o
Limitations
Interval Domain often overshoots and computes wildly overapproximated solutions.
Example 1:
flowchart LR
v1((v₁))
v2((v₂))
v3((v₃))
o["[-1,1]"]
v1 --[0,1]--> v2 --[-1,0]--> v3 --> o
v1 --[0,1]--> v3
So we can see that Expected abstract transformer should be: But returns since it does not know the relation between and .
Example 2:
flowchart LR
v1((v₁))
v2((v₂))
v3((v₃))
o1["[0,1]"]
o2["[0,1]"]
v1 --[0,1]--> v2 & v3
v2 --> o1
v3 --> o2
are both relus. is the desirable result However, is the result. tells us that for inputs between and , the neural network can output where which is a loose approximation, we needed .
We cannot capture set of points where and , instead we can give , syntactically an abstract element in the interval domain is captured by constraints of the form:
Every inequality involves a single variable and fails to capture relationships so interval domain is called non-relational. To address these limitations we will be turning towards Zonotope-based abstraction methods.
Zonotope: Relational Abstract Domain
Assume that we have a set of real-valued generator variables . A zonotope is the set of all points in the set
where . For 1 generator variable:
This is just defining an interval of the form , assuming . In the defined interval, is the centre. For a one dimensional zonotope this can be interpreted as the point being stretched in both the available directions with the magnitude of .
Zonotopes are more expressive from and above. Thus, similarly for multiple generator variables, we can observe the same “stretching” effect. The initial coordinates are stretched into a line which represents a specific vector with endpoints at and . The vector is then stretched by another generator into a parallelogram. The more generator variables there are, the more faces there are in the resulting zonotope. However each zonotope can be described a convex figure resulting from the summation of different parallelograms.
 The name zonotope is derived from zona meaning ‘belt’ in Latin. Zonotopes are named such as we can trace an uninterrupted path through the parallel vectors that wrap around the figure like a belt.
The name zonotope is derived from zona meaning ‘belt’ in Latin. Zonotopes are named such as we can trace an uninterrupted path through the parallel vectors that wrap around the figure like a belt.

In n-dimensions, a zonotope with m-generators is the set of all points
Example: Centre will be , the centre of the zonotope is always the vector of the constant coefficients.
Two dimensions are equal, so we get a line shape centred at . Zonotopes allow us to model relational intervals with the help of the generator variables. Above we see a zonotope modelling an interval that follows .
coefficients of are so it stretches the centre along the vector
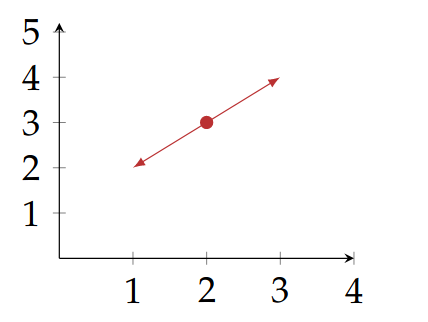
coefficients of are so it stretches all points along vector
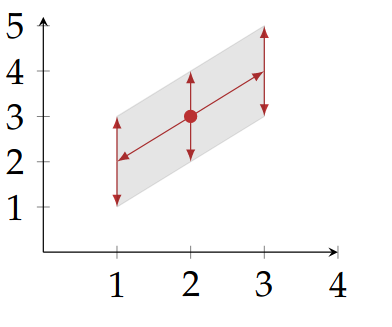
Above is the final zonotope, adding more and more faces adds more faces to the zonotope.
We will use a compact notation to signify the above equation, it will be defined as a tuple of vectors of coefficients
for an even more compact notation
where ranges from to , the number of generators. We can compute the upper bound of the zonotope in the th dimensionby solving the following optimization problem:
which can easily be solved by setting to if and otherwise.
Similarly, we can compute the lower bound of the zonotope in the j-th dimension by minimizing instead of maximizing, solving the optimization problem by setting if and otherwise.
Example:
Upper Bound in vertical dimension:
Define:
compare to
output zonotope is the set which is the interval .
Affine Functions
where .
Abstract Transformer of Activation Functions
For intervals domains we had:
This formulation does not know how the inputs are related to their corresponding outputs. Geometrically the interval domain of ReLU approximates the function with a box as shown below:
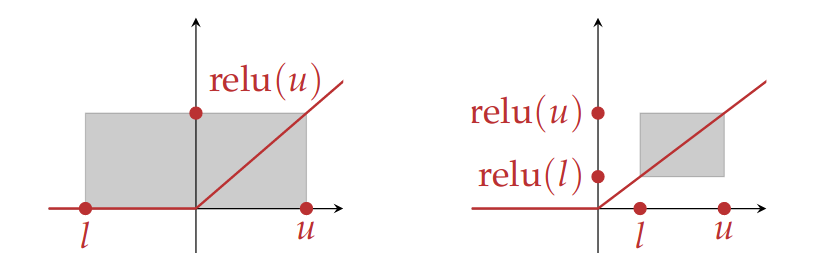 The breadth of the box depends on the lower bound of the interval, i.e., whether is positive or negative. Using zonotopes, the ReLU abstract transformer is build using a 1-dimensional zonotope as input
The breadth of the box depends on the lower bound of the interval, i.e., whether is positive or negative. Using zonotopes, the ReLU abstract transformer is build using a 1-dimensional zonotope as input
If the lower bound is greater than zero, we return the input, if the upper bound is lesser than or equal to zero we return zero. Since zonotopes allows for relating input and output, we can shear the rectangles to form better approximations of ReLU.
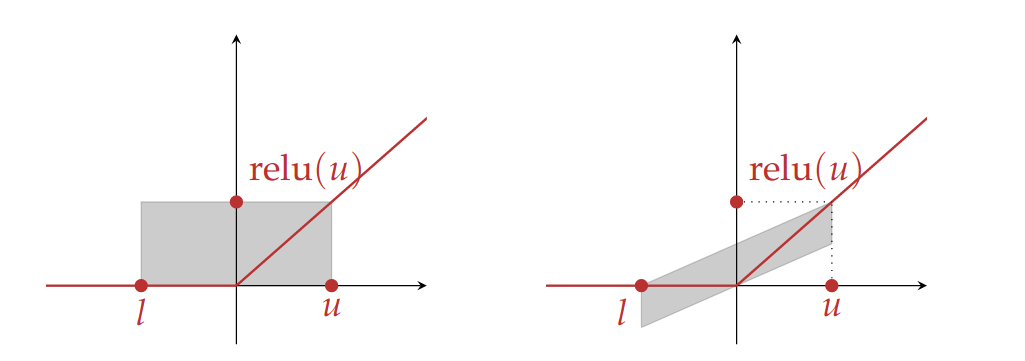
The bottom face of the zonotope is , for some slope . The top face is . For , we get the base rectangle that is the interval domain for the ReLU, the steepness of the shear depends on the parameter, which cannot be more than to ensure that the parallelogram covers the ReLU along the input range . The distance between the top and bottom faces of the parallelogram is , Thus the centre of the zonotope is at the point
With this information, we can now complete the definition of as follows:
we have added a new generator, , in order to stretch the parallelogram in the vertical axis; its coefficient is , which is half the height of the parallelogram. We also add the input zonotope scaled by with coefficient for the new generator to ensure that we capture the relationship between the input and output.
Neural Polyhedron Abstraction
So far we have been approximating functions using a hyperrectangle with interval domains but it was non-relational, the zonotope domain allows us to approximate functions using a zonotope, e.g., a parallelogram and capture relations between different dimensions. The polyhedron domain is a more expressive abstract domain as it enables us to approximate functions using any arbitrary complex polyhedra. A polyhedron in is a region made of straight faces. Convex polyhedra are shapes that have any two points of the shape completely contained in the shape and can be specified as a set of linear inequalities. This approximation is more precise for ReLU functions than those afforded by the interval and zonotope domains as the shapes used to approximated are not limited to hyperrectangle or parallelograms.
Polyhedra are defined in a manner analogous to a zonotope abstractions, using a set of generator variables, which are then bounded by a set of linear inequalities instead of being limited to the interval as is the case for zonotopes.
A zonotope in
where is a Boolean statement that evaluates to iff all of its arguments are in . For a polyhedron is defined as a set (conjunction) of linear inequalities over the generator variables, e.g.,
defines a bounded polyhedron over the generator variables, giving a lower and upper bound for each generator, e.g., is not allowed, because it does not enforce a lower bound on . In the 1-dimension, a polyhedron is simply an bounded interval.
To find the upper and lower bounds of a polyhedron, we need to solve a linear program which takes polynomial time in the number of variables and constraints.
To compute the lower bound of the -th dimension, we solve for the following:
Similarly to calculate the upper bound of -th dimension, we just take the instead of minimizing the generator terms.
A given polyhedra in
will be abbreviated as:
Example: Given polyhedron:
From the Boolean function we can understand that a bounded x-y space is being defined. For ease of visualisation, we can replace and with and which gives us a set pf equations that and must satisfy:
This set of equations clearly defines a LP problem in the shape of a triangle situated in the first quadrant of the x-y plane. Thus the polyhedron comprises of all of the points inside this triangle.
We need to solve for the following four equations to get the upper and lower bound on the generators
Thus the valid interval domains of the generators are: and .
Abstract Transformers for Polyhedra
Affine Functions
For an affine function We will have the following abstract transformer:
the set of linear equalities does not change between input and output of the function.
Example:
The abstract transformer for ReLU generated in polyhedron domain:
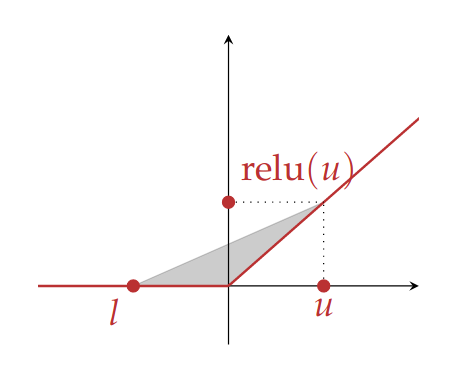
in convex polyhedra
Top face: from the equation of a straight line, where , and , .
We need to compute the shaded area which is bounded by from below, from the right, and from above. We define as
where
- and are the lower and upper bounds of the input polyhedron that can be computed using linear programming.
- is being used to denote the full term .
- And a new generator, has been added, the new set of constraints relates this new generator to the input, effectively defining the shaded region.
Condensing the constraints into two dimensions:
where determines and determines thus,
Abstractly Interpreting Neural Networks
-
For every input node , we have
-
For every non-input node we have where is the abstract transformer of , has incoming edges and
-
output of is the -dimensional polyhedron , where are the output nodes and
Some abstract transformers for activation functions add new generators, we assume all of them were already in the polyhedron but with coefficients set to , they get non-zero coefficients only in the output of activation functions.
Abstract Interpretation based Verification
For verification using the Hoare triplet to work, we require the a sound representation of the set of val of in the abstract domain. Along with the abstract representation of the neural network on all values of that results in an over-approximation of the values of . We also need to check that all values of satisfy the postcondition.
The generic precondition can be defined as:
Here for the sake of generality, we do not specify a particular norm, instead we define an -norm. The main norms that we will be considering in this case are the -norm and the -norm both of which are distance metrics but serve very different purposes.
-norm is the length of the straight line between two images in and -norm is the largest discrepancy between two corresponding pixels. They have their own usability based on what kinds of deviations we wish to categorize. If there is a great deal of variability restricted to some locality of the image we can use -norm as it allows a small number of pixels to significantly differ in brightness. If the noise is random and spread out through the entire image, -norm is more suitable as it bounds the maximum discrepancy a corresponding pixels in the two images can have.
Abstracting the Precondition
We have the precondition as:
Interval: allows us to take elements of and change it by independently of other dimensions. Define abstract transformer
represents all possible values of and more.
We have to prove that , We see that if then,
If -th interval is larger than all others, then we know that the classification is always .
Note: if for some , then we cannot disprove this property, so this is a one-sided check. In simpler words, since we will be receiving a range of probabilities corresponding to each of the class indices. We will be choosing the class whose lower bound probability () is higher than all other upper bounds of all other class (). We will be picking the non-overlapping bound with highest lower bound. If there is any overlap between the range of probabilities, we cannot be entirely sure as to which class the resulting probability belongs to inside of the overlapping region. Thus making this is a one-sided check.
 Example:
Example:
where
two intervals overlap in the 0.15 to 0.2 region, this means that we cannot conclusively say that , so verification fails. that can belong to both and .
Verifying Robustness with Zonotopes
Checking robustness property using zonotopes. Since precondition is hyperrectangular it can be precisely represented:
we want to ensure that the dimension is greater than all others, problem is akin to checking if a 1-D zonotope is always > 0.
To check that dimension is greater than dimension , we check if the lower bound of the 1D zonotope is > 0 or not
Example: For this region, we can graphically see that for any point To check mechanically, we subtract the -dimension from the -dimension.
The resulting 1D zonotope denotes the interval which is greater than zero.
So, for multiple -generators and -dimensions
for some -dimension check for every and check whether
(we will be getting a set of ranges, if every range > 0 then is the class)
Verifying Robustness with Polyhedra
Analogous to zonotopes but requires invoking a linear program solver.
We represent the interval as a hyperrectangle polyhedron . Then we evaluate resulting in a polyhedron
To check if dimension is greater than dimension , we ask a linear program-solver if the following constraints are satisfiable
Robustness in -norm
: this defines a unit circle around .
let
Cannot be precisely represented in the interval domain, best we can do is with polyhedra, we can define polyhedra with more and more faces to more accurately approximate a circle, but there is a precision-scalability trade-off that comes into the picture.
Robustness in NLP
Synonyms of words should not confuse Neural Networks. Complete set of synonyms: ; each word is -th element of a vector is the -th token/word embedding of the sentence
Correctness Property:
all vectors that are like but where some words are replaced by synonyms. Set of possible vectors is finite but exponential in length of input sentences
Abstract Training of Neural Networks
Training Data: binary label (classification model):
We assume we have a family of functions represented as a parameterized function: Where is the vector of weights. Search the space of and find the best values of .
Family of affine functions:
Solve optimization problem:
This function is difficult to resolve as Boolean is non-differential so we use MSE:
family of functions represented as neural net graph , where every node ‘s function may be parameterized by . Formally we solve:
Loss function can also be represented as a neural network. is represented as an extension of the graph by adding a node at the very end that computes the loss function.
flowchart LR
v1[v₁] & v2[v₂] --> A((...)) & B((...))
A & B--> vo[vₒ]
subgraph "intermediate nodes"
A
B
end
We can construct a graph for the loss function by adding am input node for the label and creating a new output node that compares the output of (the node ) with .
flowchart LR
v1[v₁] & v2[v₂] -.- vo((vₒ)) --> vL[v_L]
vy[v_y] --> vL
input node takes in the label and encodes the loss function, e.g., MSE
Gradient Descent:
- Start with and a random value , called
- Set to
- Set to and repeat learning rate
Set to
SGD/mini-batch gradient descent:
- Start with and a random value , called
- Divide the dataset into a random set of batches:
- For from 1 to :
- Set to
- Set to
- reiterate
Size of batches is dependent on how much data can be put into the GPU at any one point.
These optimization algorithms do not provide any robustness to the networks, as we are only minimizing loss over average prediction. Not robust to perturbations, even if they are, abstract interpretation fails to provide a proof due to its overapproximate nature. So we would like to train neural networks in such a way that they are friendly to abstract interpretation.
Redefining Optimization Objective for Robustness
(Robustness Optimization Objective)
For every in our dataset, we want the neural net to predict on all images such that . This set can be characterized as
New Optimization Objective
Instead of minimizing for the loss of , we minimize loss for the worst-case perturbation of from the set . This is known as robust optimization problem. Training the neural net using such an objective is known as adversarial training (very similar in appearance to minimax or other game playing techniques).
Solving Robust Optimization via Abstract Interpretation
can be defined in interval domain precisely as it represents a set of images within an bound. We can overapproximate the inner maximization by abstractly interpreting on the entire set . By virtue of the soundness of the abstract transformer , we know:
where Therefore we can overapproximate the inner maximization by abstractly interpreting the loss function on the set and taking the upper bound.
Thus the robust optimization objective can be rewritten as:
instead of treating as an abstract transformer, we can treat it as a function taking a vector of inputs and returning upper and lower bounds, this is called flattening the abstract transformer.
Example:
flattening the to
: returns a tuple of values instead of an interval.
Where is the only upper bound of output
SGD can optimize for such objectives because all of the abstract transformers of the interval domain that are of interest for neural nets are differentiable almost everywhere. Some can be adapted into zonotopes also.
Example:
Flattening does not work for polyhedra domain, because it invokes a blackbox linear programming solver for activation functions which is not differentiable.
Neural Networks trained with abstract interpretation are:
- more robust to perturbation attacks
- verifiably robust using abstract interpretation A Neural Network could satisfy a correctness property but we may not be able to verify the neural net using abstract domain. By incorporating abstract interpretation right into the training we guide SGD towards neural nets that are more amenable to verification.
Note: robustness properties are closely related to the notion of Lipschitz continuity. For instance, a network is K-Lipschitz under the -norm if
The smallest K satisfying the above is called the Lipschitz constant of . If we can bound K, then we can prove -robustness of .