Info
Consider a set
is some subset of the set , the complement of this subset can be demonstrated as .
Broadcasting:
Elements of are added to each row of the matrix .
Since dot product gives a scalar it is a commutative operation in the following way:
Matrix Multiplication
(each element in the matrix is calculated via a dot product of th row of and th column of .)
If and are solutions to , then is also a solution for any .
Info
A visualization for can be seen as:
determines how much to go in direction.
Therefore for each element of the resulting vector we will have , where is a scalar multiplication of and all elements of the column vector.
The vector-matrix multiplication operation can be translated into a linear combination of the column vectors of the original matrix, multiplied with each element of the vector column:
From the above, we see that will be a solution of only when it is in the column span (range) of .
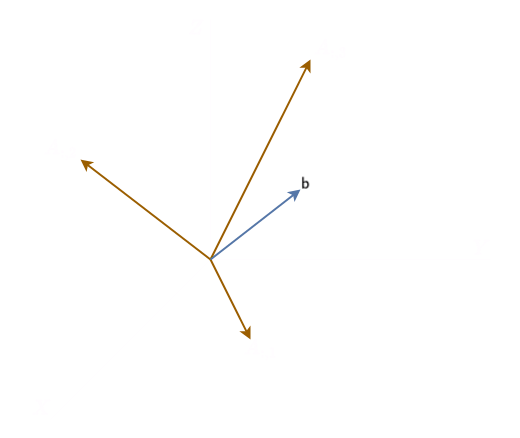
can be thought of as being pulled quantity in direction times in direction and times in direction. We need to have at least independent columns in order to define as their column space ().
if is a matrix and is , is 2-dimensional, so defines only a 2-D plane within , the equation has a solution iff lies on that plane.
flowchart TD
a["conditions"] --> b["have to at least describe m-dimensions"] & c["m-vectors should be linearly independent"]
b --> c
: at most one solution for each value of
If overdetermined (), there is more than one way to parameterize the solution.
Any Norm function will be of the following form:
Note
Norm are generally a way of measuring distance which scales from scalar multiplication.
norm which corresponds to the number of non-zero entries in a vector is not a valid distance metric as scaling the vector by does not change the number of non-zero entries.
Infinity Norm:
This norm measures the maximum discrepancy between two elements in a vector.
Frobenius Norm:
Frobenius Norm is considered w.r.t a matrix, for vectors (or single column matrices) this will be equivalent to the norm of the vector.
Vectors having and are called orthonormal vectors.
Diagonal Matrices: Diagonal Matrices have only diagonal elements, rest are all zeroes.
For a non-square tall diagonal matrix zeroes are added to the end of the matrix. For a wide matrix, elements of are dropped during multiplication.
Symmetric Matrices:
Singular Matrices: Square matrices with linearly dependent columns.
Orthogonal Matrices: rows (columns) mutually orthonormal
Eigenvectors and Eigenvalues
Matrix has linearly independent eigenvectors and corresponding eigenvalues .
Concatenating the vectors (one vector per column):
Eigendecomposition:
For any Real Symmetric Matrix we have:
where is the diagonal matrix of eigenvalues and is orthogonal matrix of eigenvalues of . Eigendecomposition is guaranteed for real symmetric matrices, but they might not unique.
is eigenvalue related to th column of ( ), since it’s orthogonal (independent basis) we can think of as scaling space by in direction . If , matrix is singular.
where is eigenvalue corresponding to the specific eigenvectors.
: A matrix whose eigenvalues are all positive : positive definite
: A matrix whose eigenvalues are all positive or zero : positive semidefinite
A matrix whose eigenvalues are all negative : negative definite
A matrix whose eigenvalues are all negative or zero : negative semidefinite